Meet Punyo, TRI’s Soft Robot for Whole-Body Manipulation Research
By Alex Alspach and the Punyo Team

The Punyo Team: Alex Alspach (Tech Lead), Andrew Beaulieu (Tech Lead), Kate Tsui (Tech Lead), Jose Barreiros, Aditya Bhat, Bisi Chikwendu, Sam Creasey, Eric Dusel, Aimee Goncalves, Manabu Nishiura, Aykut Önol, and Leticia Priebe Rocha
“Meet Punyo” Introductory Video (YouTube)
At TRI, we’re developing robotic capabilities that amplify, rather than replace, people. We’re on a mission to help with everyday tasks that require more than just our hands and fingertips.
Our research platform, Punyo, embodies this mission. The Punyo team is focused on bulky object manipulation using the arms and chest to complement TRI’s other efforts in fine robot hand- and gripper-based dexterity. We are developing hardware and algorithms that enable truly capable robots to help with large, heavy, and unwieldy items.
People use their bodies in creative ways to manipulate the world around them. Think about getting groceries into your house in just one trip. You might hold multiple bags in your arms, open the door with your elbow, and then prop it open with your hip as you shuffle in. It’s easy to imagine other tasks, too, such as lifting and stowing large boxes, moving furniture, or collecting piles of laundry, where you use your chest, arms, and other body parts to get these jobs done.
For people and robots alike, having soft grippy skin and manipulating objects close to the body make it possible to handle heavier objects with less exertion. Still, it’s common to see today’s robots carrying heavy objects using only their hands, which is inefficient. Punyo does things differently; it isn’t afraid to make a lot of contact, utilizing its whole body to carry and manipulate more than it could by grasping with only outstretched hands.
What’s a Punyo?
Punyo is our robot’s name. In Japanese, the word “punyo” (ぷにょ) describes something soft, cute, and resilient. It represents our philosophy on what Toyota’s future home robots should be: safe, capable, and a pleasure to work alongside. While this approach to robotics can take many forms, the vision that motivates us is a friendly humanoid built to take on day-to-day challenges safely at home.

The Punyo Hardware Platform
Punyo’s hands, arms, and chest are covered with compliant materials and tactile sensors so it can feel contact. The softness allows Punyo to conform to the items it’s manipulating, enabling stability, increased friction, and evenly distributed contact forces. Tactile sensing allows Punyo to apply controlled forces on objects, sense contact (both expected and unexpected), and react to object slips and bumps. Tactile sensing is also important for interacting with people. Whether lifting heavy objects or physically assisting people, robots should be aware of their own bodies and interact appropriately.
While Punyo is considered a soft robot, underlying its softness are two “hard” robot arms, a rigid torso frame, and a waist actuator. Our approach combines traditional robots’ precision, strength, and reliability with the compliance, impact resistance, and sensing simplicity of pneumatic soft-robotic systems.
From shoulder to wrist, Punyo’s arms are covered in air-filled bladders, or “bubbles,” similar to the flesh covering our bones. Each bubble connects via a tube to a pressure sensor which senses forces applied to the outer surfaces of the bubbles. Each of the bubbles (13 on each arm) can be individually pressurized to a desired stiffness, and add about 5 cm of compliance to the surface of the robot arms. This is an inexpensive, lightweight, and modular approach to adding compliance and tactile sensing to large surfaces of robots.

The bubbles covering the arms are built using molded heat-sealed PVC panels. A single large bubble covers Punyo’s wrist without limiting the robot’s ability to move the joints underneath. The rest of the arm bubbles are six smaller rings comprising two chambers each, one chamber on the inside of the arm and another on the outside. Covering the arms are tailored fabric sleeves that protect the bubbles, prevent cable snags, and allow us to iterate on outer contact-surface materials. The sleeves are easily removable for maintenance and provide an opportunity for aesthetic customization.
Punyo doesn’t have grippers so there are no fingers or thumbs. Not yet, at least. Instead, Punyo has “paws.” Each paw is a single high-friction latex bubble with a camera inside (based on TRI’s soft-bubble visuotactile sensors, punyo.tech/bubblegripper). Printed on the inside of these bubbles are dot patterns. When the bubble makes contact with something, the dot pattern deforms. The internal camera uses this deformation to estimate forces and feeds the images directly to learned visuomotor policies.
Teleoperation Tools for Teaching Whole-Body Skills
We put our hardware to the test on various whole-body tasks. Punyo learns contact-rich policies using two powerful methods: Diffusion Policy and Example-Guided Reinforcement Learning. To try out new tasks directly on hardware and provide example demonstrations to these learning pipelines, we are developing intuitive teleoperation interfaces for whole-body skills. Diffusion Policy, announced by TRI last year, uses human demonstrations to learn robust sensorimotor policies (using camera and tactile feedback) for hard-to-model tasks. Example-Guided Reinforcement Learning (EGRL) requires tasks to be modeled in simulation and a small set of demonstrations to guide the robot’s exploration. Both methods produce robust policies that exploit compliance and incorporate tactile feedback.
Grasp Synergy Teleop: For core whole-body manipulation tasks, such as grasping and lifting, we’ve broken these skills down into synergies, similar to synergies for hand-based grasping, which are motions we individually control via a gamepad interface. We combine independent raising and lowering of the arms with opening and closing of each arm’s grasp to create single and bimanual grasps, re-grasps, and arm gaiting for lifting and in-grasp manipulation. Requiring only a standard, low-cost gamepad, demonstrations can be performed anywhere in the lab and in the wild.
Hierarchical Operational-Space Teleop: For more complex, precise, or nuanced tasks, direct control over the paws, elbows, and torso angle can help. Controlling these allows us to, for example, lean forward to gather items against our chest, wrap one arm over an object with the other placed underneath, and lean backward to lift. We use motion capture cameras to track markers placed on our teleoperator’s back, shoulders, elbows, and handheld paws, corresponding to similar points (operational points) on the robot. The teleoperator’s motions are retargeted to Punyo, allowing anyone to operate the system regardless of body proportions.
We use a hierarchical whole-body motion control approach for teleoperation and for rolling out autonomous diffusion policies. During teleoperation, for example, end-effector pose tracking is our highest priority task so that Punyo’s paws reliably track the teleoperator’s paws. Elbow pose tracking can be secondary, allowing Punyo to achieve teleoperated elbow poses as long as they don’t interfere with the higher-priority end-effector tracking. Using a hierarchical motion control framework allows us to quickly iterate on our teleoperation interface by adding, removing, adjusting, and reprioritizing constraints and operational point tracking.
The hierarchical framework also provides an interface for exploring physically reactive motions and human-robot interaction. An example is Punyo moving its elbow out of the way when an accidental bump is sensed. Because of the redundant joints in our arms, we can move the elbow without sacrificing end-effector motion. This control scheme can be used to allow a person to push Punyo’s arm out of the way mid-task to quickly grab something.

Right: Teleoperation tracking shoulders, elbows, and paws.
Guiding Reinforcement Learning with Human Examples
We use Example-Guided Reinforcement Learning (EGRL) to achieve robust manipulation policies for tasks we can model in simulation. Providing demonstrations of the task makes the learning process more efficient and allows us to influence the style of motion the robot uses to achieve the task. We use Adversarial Motion Priors (AMP), traditionally for stylizing computer-animated characters, to incorporate human motion imitation into our reinforcement learning pipeline. All policies shown below were trained with just one demonstration.
Our pipeline exposes a variable, λ, that is the ratio of demonstration imitation reward to task objective reward. This variable allows us to balance how much Punyo learns to mimic motions as demonstrated versus learning to succeed at the task purely through exploration. Take, for example, learning the task of lifting a large jug up onto the robot’s shoulder. Turn the dial one way (λ = 0), and the robot just “goes through the motions,” imitating human-demonstrated movements for the same task with no regard for whether or not the jug leaves the table. Turn the dial the other way (λ = 1), and the robot disregards the demonstration altogether, focusing only on getting the jug off the table and converging (hopefully) on any unnatural motion that gets the job done. A λ somewhere in between produces a policy that completes the task in the style of the demonstration.
The task description can be more complex than just lifting a jug. For example, we can also incentivize speed, low-energy consumption, or more robust task completion. Blending functional requirements with a human-demonstrated style may result in a robot that is efficient yet easier for people to predict and anthropomorphize, allowing them to collaborate more comfortably and productively. We look forward to discovering the right balance for various tasks, situations, robots, and human collaborators.


Plan-Guided Reinforcement Learning
Reinforcement Learning requires our task to be modeled in simulation for training. We can therefore use a model-based planner for demonstrations instead of teleoperation. We call this Plan-Guided Reinforcement Learning (PGRL). Utilizing a planner makes longer-horizon tasks that are difficult to teleoperate possible. We can also automatically generate any number of demonstrations, reducing our pipeline’s dependence on human input, which is a step toward scaling up the number of tasks Punyo can handle. This capability may someday enable Punyo to learn new skills on its own.
While state-of-the-art model-based planners can produce motion plans with complex contact sequences, they aren’t nearly fast enough to be employed online in a closed-loop fashion. Further, due to model inaccuracies and assumptions, the plan may not be physically feasible even in simulation. We are, therefore, left with trajectories that will likely not manipulate target objects as intended (if at all) when played open-loop on robot hardware. However, we can use example-guided reinforcement learning to take this rough trajectory and turn it into a feasible feedback policy.
We use a contact-implicit planner for synthesizing long-horizon behaviors with many intermittent contacts. The planner makes some assumptions to enable global contact reasoning that prevent its output from working on hardware directly. However, the trajectories are a great demonstration of the needed motions and contact sequences for seeding our EGRL pipeline. With a task objective, domain randomization, and this rough demonstration to guide the motion exploration, Punyo can efficiently learn a closed-loop policy that takes after the motion plan to perform difficult tasks robustly on hardware.


Towards Safe and Productive Collaboration
While dexterous capabilities are surging at TRI and elsewhere, today’s robots and manipulation strategies leave many tasks and skills out of reach. There’s more work to be done with objects too big for our hands, piles of items our arms must stabilize, objects held in one arm while manipulating others, and the ability to operate safely in confined spaces and around people. Developing hardware, knowledge, and datasets for whole-body manipulation in parallel with gripper-based dexterity is important to create a diversely capable manipulation platform.
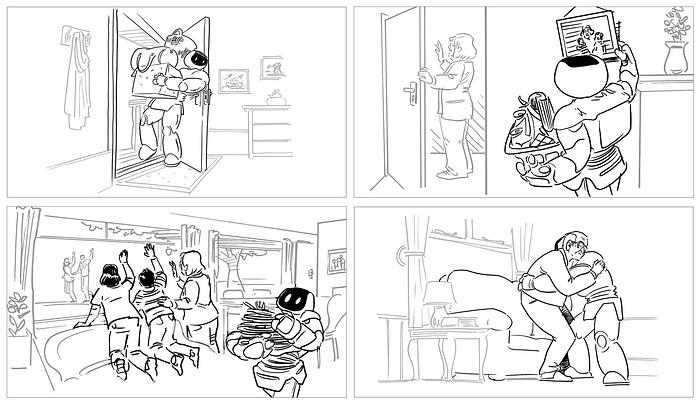
Unlocking a robot’s chest, arms, and other body surfaces for manipulation is mechanically advantageous. Coupled with compliance and friction, a robot can hold and manipulate large objects with less energy, increasing payload and battery life and enabling lower-cost systems. Being soft, it can absorb impacts, both for the safety of the robot and the people around it. Adding tactile sensing, it can closely monitor and control contact forces, leading to gentle, complex, interactive, and stable manipulation.
TRI’s Punyo team was built to solve this problem. Our experts in soft robotics, contact-rich planning and learning, tactile sensing, and human-robot interaction are dedicated to a future where robots and people collaborate safely, productively, and happily side by side.
Acknowledgments
Special thanks to Russ Tedrake, Toffee Albina, Max Bajracharya, Gill Pratt, Kunimatsu Hashimoto (for naming Punyo!), Ben Burchfiel, Alejandro Castro, Eric Cousineau, Hongkai Dai, Richard Denitto, Evelyn Dixon, Jimmy Dornier, Sera Evcimen, Siyuan Feng, Chris Gidwell, Stacie Gidwell, Damrong Guoy, Brendan Hathaway, Allison Henry, Phoebe Horgan, Jenna Hormann, Steve Iacovino, Lukas Kaul, Naveen Kuppuswamy, Alyssa Lau, John Leichty, Susan Michael, Gordon Richardson, Paarth Shah, Lisa Tobasco, Avinash Uttamchandani, Tristan Whiting, Jarod Wilson, Jon Yao, Mengchao Zhang, Alex Alexanian, Reed Alspach, Will Knight, Liz Perlman, and our babies and significant others ❤

